

Content management systems and web software are now significantly smarter and better at outputting code than they were a mere few years ago, so it’s easy to trust that they will generate clean, efficient code with no human editing necessary. In practice, they often need their work checked. As a programmer, I often run into situations like this: “Why is that huge white gap below the text on this page?” I open the page. I inspect the HTML. Below the content are 5 empty paragraphs which should not be there.
Formatting HTML correctly is still important. Improper formatting may not always break the entire site, but often, it simply won’t look as nice because it will fight the site’s stylesheet, or be more difficult for search engines and screen readers to understand. “Clean Code” simply means making code that is efficient, is not bloated with unnecessary information, is formatted properly, and is not broken. When done, sites perform optimally.
Basic Structure
The basic structure of HTML is called the “Box Model” because it works like a set of nested boxes. Each html “box”, or tag, opens with its name in < > and closes with its name in </>. Example:
<p></p>
<div></div>
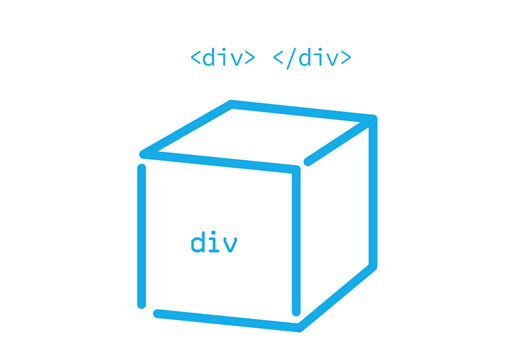
Just like a box, it can hold many smaller boxes. (Unlike a box, there’s no limit to how much it can hold!)
However, a box cannot be both outside and inside the box that is holding it. It’s also important to close tags properly, to not leave half a box. Sometimes the browser is smart enough to close them on its own (<div> <p> </div> would pass) but it is not good practice to leave them open.
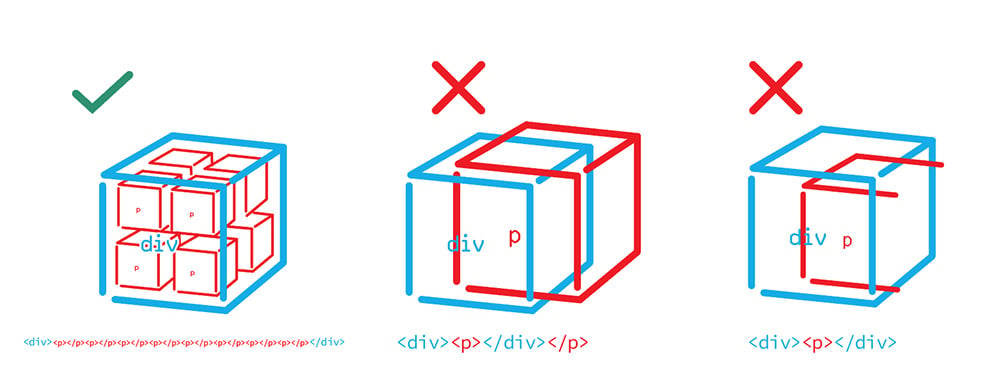
When planning web content, it is best to keep the box model in mind from the start, to avoid any tricky situations where the intended effect fights realistic structure constraints.
For example, putting a hyperlink around an image and only half of the paragraph under it creates a box that breaks the box model:
<a> <img/> <p> Some </a> Text</p>
In order to fix this, the image should be nested inside the paragraph tag with the hyperlink, or the hyperlink should be removed from the image.
<p> <a> <img> </a> Some Text </p>
<img/> <p> <a> Some Text </a> </p>
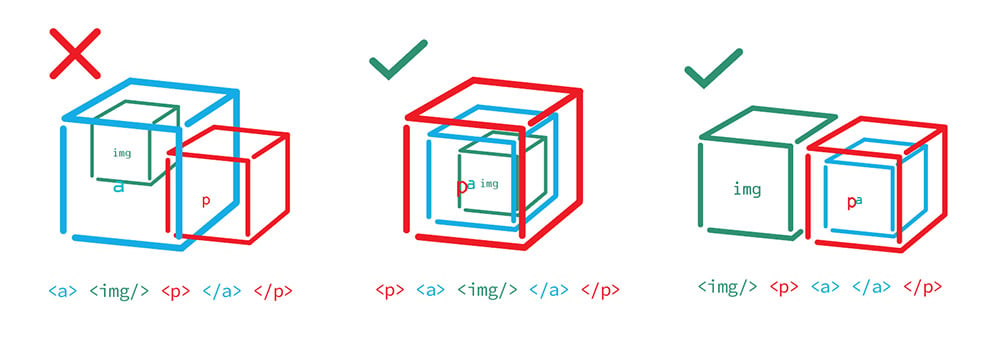
The goal is to make sure each box is packaged neatly in its parent box. When working with content management systems or automatic html generators, they will usually try to fix any unusual code automatically—with often messy results. Example:
<a><img/> </a> <a> </a> <p> <a> Some Text </a> </p>
Not clean at all! Be nice to the content management system, and it will be nice to you.
Formatting Text
The core text formatting tags in HTML are the paragraph tag <p> and the heading tags <h1> <h2> down through <h6>. Just like paragraphs or headers in print media, these are units of content. Header tags should not be wrapped inside paragraph tags.

For best results, header tags should be used for headers, and paragraph tags should be used for body copy paragraphs. Header tags ought to be organized from the first level down, so if the page title is a H1, all the sections should be H2, then their subsections should be H3. Levels should not be skipped or started randomly in the middle. Note: when writing content for a page that already has a H1 title, such as “About Us”, the content sections can and should start with H2, not H1.

A line break, <br />, breaks the line in the middle of a paragraph or header. It is a self-closing tag, meaning the <br /> tag is at once the opening and closing tag—it’s not a box, it is a flat sheet of paper. Most correctly, it breaks an address or other content that needs more than one fixed-length line without separating it into paragraphs, so that the content stays together as a single unit.

Used between paragraphs, <br/> will have the same effect as putting in another paragraph of empty space, without any padding the stylesheet applies to the paragraph. (I recommend using <p> </p> instead if an extra paragraph’s worth of space is absolutely necessary.) However, when trying to remove unwanted spaces between content, look out for both rogue paragraph tags and line breaks.

is a non-breaking space. Used between two words, it will prevent them from being separated when the line breaks, so they stay on the same line. It can also be used to create more space between words that need to be separated, since code reads multiple plain spaces as a single space. Multiple are another culprit to watch out for when cleaning automatically generated code.

HTML also provides several tags for formatting text within paragraphs or other text units. The most common are:
<span> – is a content-grouping tag, and doesn’t affect the way the text is read—it is generally used for styling, such as making two specific words in a paragraph red.
<em> – is the emphasis tag and displays in italics.
<strong> – means the content ought to be read strongly and displays in bold text.
All of these should be properly corralled within their paragraphs; avoid cases like <p> <em> </p> </em>.

Formatting Images
The basic image tag is another self-closing tag. Its fundamental components are the <img /> tag itself and the src attribute, which points to the location of the image. An attribute adds extra data to a tag, consisting of the name of the attribute, then an equals sign, then the attribute contents in quotes. Some attributes, like src, are vital to the tag operating correctly.

Some content management systems add extra attribute data relevant to their system. It is alright to leave this data in. (example from Sitefinity.)

Alt Text
Another important component of images is the alt attribute, which goes in the image tag, typically after the src. The alt text will give screen readers something to read instead of leaving visually impaired users questioning. It will also display as plain text where the image would normally insert if the image breaks or fails to load, which can be helpful for locating a replacement if the source image gets moved or deleted. Because the alt text will not affect the look of the image or be visible normally, there are no cons to adding it, only pros.

Even when overwritten by the styling, height and width attributes should be specified on images for performance optimization. The syntax for a 750 pixel by 500 pixel image would be width=”750″ height=”500″. Note the lack of “px” after the numbers.

Hyperlinks
The hyperlink tag creates a clickable link from one page to another or between various parts of a page. A basic hyperlink tag consists of its opening and closing <a> tags, and a href=”” attribute which points to the location linked.

Again, content management systems often add extra data to the link tag that should be left in.
Telephone numbers can be made clickable for mobile by setting the href attribute to the phone number, preceded by “tel:”.
Similarly, email links can be created by typing the email address in the href attribute after “mailto:”.
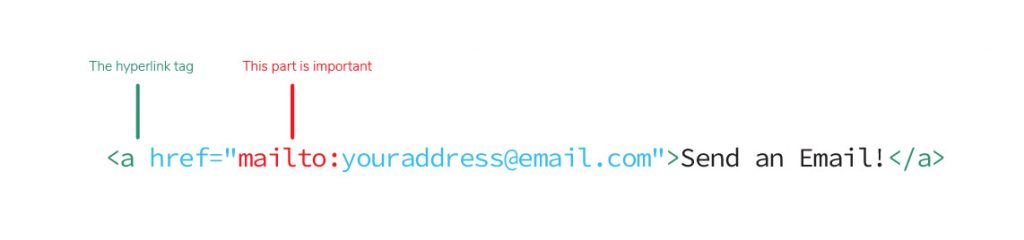
The unassuming hyperlink is one of the most common tags to forget the box-model for, so thoughtfulness when placing them can save a fight with the content manager. Content management systems also sometimes generate extra empty hyperlinks when a hyperlink is replaced, so, if using a content management system, it is best to inspect the html after switching a link.

Lists
Lists come in two types: ordered and unordered. Ordered lists are appropriate when the content must come in numbered steps; unordered lists when the content does not depend on a specific order.

When working with lists, no tags should come between the list parent and the list children, so a list item with a hyperlink should be written <li> <a> </a> </li>, not <a> <li> </li> </a>.

After using automatically generated code, it helps to tab into the HTML editor to make sure it is clean, especially if the output doesn’t look quite right. Once familiar with HTML’s structure and rules, it is a mere second’s work to remove those five empty paragraphs or that extra link and clean up the code. Formatting it properly will help the content get delivered more smoothly to all users–a small step for a better user experience.
Did you like this blog post?
Get more posts just like this delivered twice a month to your inbox!
